Figuring out which Simpsons character is speaking
Update: you can find the next post in this series here.
You probably have a favorite Simpsons character. Maybe you hope to someday block out the sun, Mr. Burns style, maybe you enjoy Homer’s skill in averting meltdowns, or maybe you identify with Lisa’s struggles for acceptance. Through its characters, the Simpsons made a huge impact on a generation, and although the show is still running, my best memories will be of the early seasons.
I recently wanted to do some linguistic analysis of Simpsons episodes. To my surprise, I found that it is impossible to find Simpsons episodes scripts with information about who is speaking which line. You can find episode capsules on snpp.com, but they feature only quotes from the episodes. Simpsoncrazy has some scripts, but not enough for any real analysis. You can find complete transcripts, but they lack any information on who is speaking when.
Here is a (very confusing) sample of a transcript:
I think the boy's hurt.
Just give him a nickel and let's get going! I think we should call an ambulance, sir.
Hey, cool.
I'm dead! Please hold on to the handrail.
Do not spit over the side.
Aunt Hortense.
Great-grandpa Simpson.
I immediately set about to correct this glaring omission. Rather that sit down and manually label each episode with speaker information, I decided to use the power of the computer to do it for me. To quote Homer, Don't worry, head. The computer will do our thinking now.
I will follow this post up with a technical one, but for now, you can find all of my code here.
Get the transcripts!
Our first step is to grab the scripts and the transcripts. The scripts have the information we need (lines and who spoke them):
Moe: [answering the phone] Flaming Moe's.
Bart: Uh, yes, I'm looking for a friend of mine. Last name Jass. First name
Hugh.
Moe: Uh, hold on, I'll check. [calling] Hugh Jass! Somebody check the
men's room for a Hugh Jass!
Hugh: Uh, I'm Hugh Jass.
Moe: Telephone. [hands over the receiver]
Hugh: Hello, this is Hugh Jass.
Bart: [surprised] Uh, hi.
Hugh: Who's this?
Bart: Bart Simpson.
Hugh: Well, what can I do for you, Bart?
Bart: Uh, look, I'll level with you, Mister. This is a crank call that
sort of backfired, and I'd like to bail out right now.
Hugh: All right. Better luck next time. [hangs up] What a nice young man.
So, we have the scripts and transcripts, right? (It’s amazing how easy it is to do this step if you just decide that you have done it). We are going to use the scripts to train the computer to figure out who is speaking in the transcripts.
Just like it is difficult to decide which one of the 5000 varieties of soap at the supermarket is the correct one, it is equally difficult for a computer to decide which one of 50+ characters is speaking a line. We are going to figure out which characters talk in a similar way to others, and group them together, based on our scripts.
We can figure out which characters are linguistically similar to each other, based on our small sample of scripts:
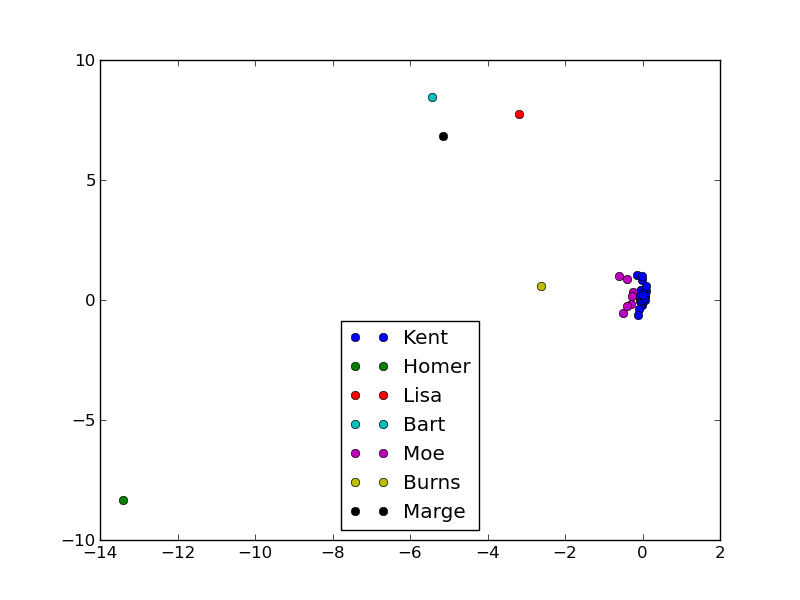 In the above, the larger clusters contain multiple characters, but they are only labelled by the first character. So, cluster “Moe” consists of:
In the above, the larger clusters contain multiple characters, but they are only labelled by the first character. So, cluster “Moe” consists of:
Moe
Ned
Smithers
Apu
Skinner
Milhouse
Grimes
So, we group them together. As we can see, the main characters are all very distinct, due to their large amount of dialogue.
Some data exploration
Let’s look at the initial data before we dive in.
We can see how many lines each character has in our scripts:
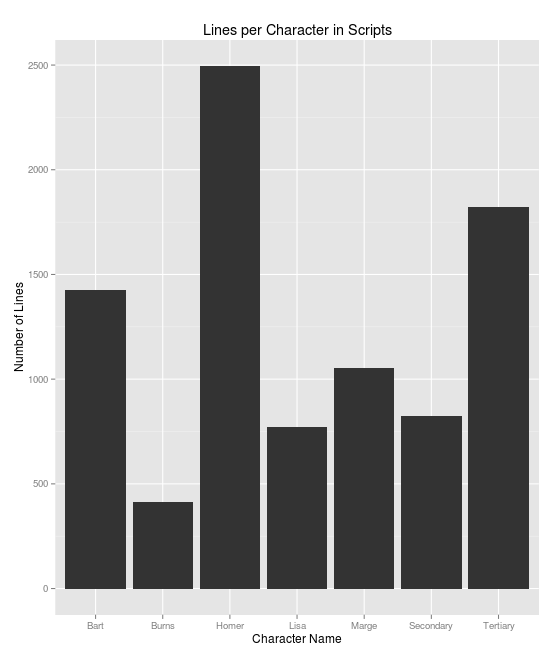 We can also see what words each character is most likely to say (more common towards the bottom). As we have always suspected, it looks like the show does, in fact, revolve around Homer:
We can also see what words each character is most likely to say (more common towards the bottom). As we have always suspected, it looks like the show does, in fact, revolve around Homer:

Make our model
We can then make a model to predict who is speaking the lines of text in the transcripts.
We can do this by applying a random forest classifier. This will tell us whether the line I think the boy's hurt. is Smithers expressing concern, or Burns delighting in causing pain (although attentive Simpsons fans already know the answer).
We also do some matching to find which lines in the scripts exactly correspond to lines in the transcripts, using the k-nearest neighbors algorithm.
After we do this, we end up with labelled transcripts:
Homer: Come on, Lisa. Say somethin' funny.
Lisa: Like what? Oh, somethin' stupid like Bart would say.
Bart: Forget it, Dad. If I ever become famous I want it to be for something worthwhile, not because of some obnoxious fad.
Tertiary: Obnoxious fad? Ah, don't worry, Son.
Homer: That little snot boy. I'd like to smack that kid!
We can also see who is speaking how many lines now:
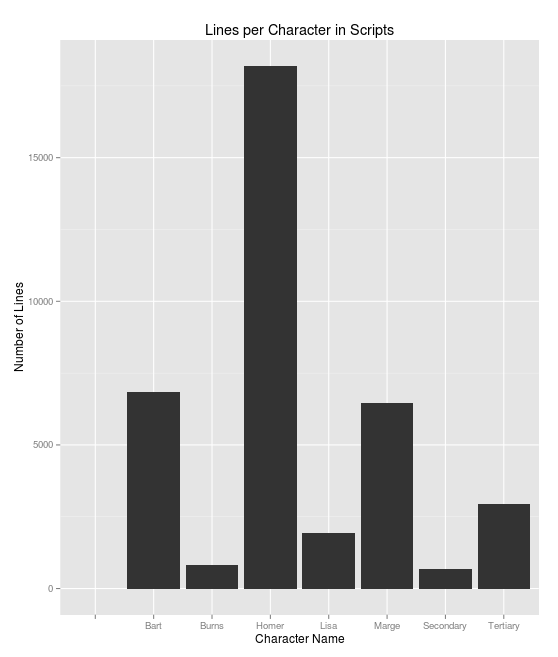 Not all of the lines have been labelled, as the lines the algorithm is uncertain about are left unlabelled. Homer is also being assigned too many lines, but the proportion is semi-close to our previous graph. We can see what the commonly said words are:
Not all of the lines have been labelled, as the lines the algorithm is uncertain about are left unlabelled. Homer is also being assigned too many lines, but the proportion is semi-close to our previous graph. We can see what the commonly said words are:
 From some of the commonly said words, we can see that some lines are being mis-attributed (lisa rarely says Homer, for instance), but it looks reasonable overall.
From some of the commonly said words, we can see that some lines are being mis-attributed (lisa rarely says Homer, for instance), but it looks reasonable overall.
We can also extract basic summary statistics, such as, there are 102066 lines in the transcripts, and 1016692 words, for an average of 9.96 words per line.
What does this mean?
"Uh-huh, uh-huh. Okay. Um Can you repeat the part of the stuff where you said all about uuhhh, things. Uhh... the things."
-- Homer Simpson
This leaves us in a good spot. We have labelled the speakers, and although it isn’t great, it is a good starting spot, and it will enable us to do some additional linguistic analysis later on (which is what I originally wanted to do).
We could potentially make this better in a lot of ways:
- Use subtitles with time information, and combine those with audio files to decide who is speaking. This is a very good option, and would get much higher accuracy.
- Add in more labelled training data, potentially with some self-labelled data.
- Tweak the algorithm.
- Clean up the input data more.
I was looking into implementing the first suggestion, but as Homer once said, There is a time for many words, and there is also a time for sleep. Well, wrong Homer, but you get the idea. I hope this was an interesting post, and I will be making another one in the future with the technical details behind this.
