On the automated scoring of essays and the lessons learned along the way
We’ve all written essays, primarily while we were in school. The sometimes enjoyable process of researching the topic and composing the paper can take hours and hours of careful work. Given this, people react badly to the notion that their essays may be scored not by a human teacher, but by machine.
A piece of software coldly judging the quality of our carefully constructed phrases and metaphors based on unknown criteria is more than most writers can bear. But is this what automated essay scoring (AES) is? If not, what is it? In this article, I aim to explore what AES is, the state of field, some of the lessons I have learned along the way, and where I think it is going.
Who am I?
I’m going to ramble a bit here, so please indulge me. I have been involved in the AES field for 2 years now, but the building blocks were laid well before that.
I didn’t know it at the time, but my interest in AES began with my own struggles with higher education. I never knew what I wanted out of my life when I was in school, and wouldn’t have seen college as the way to get there even if I had. Afterwards, this gave me a keen interest in trying to find ways to personalize learning.
I later joined the US foreign service, a career that required me to do a lot of writing (see: Wikileaks cables). I ended up leaving the foreign service, a decision that led to me learning programming and machine learning, the art of how to teach computers to predict things, through online materials. But I kept my love for writing alive.
Imagine my surprise when I found a three month long competition sponsored by the Hewlett Foundation, and hosted by Kaggle, that aimed to develop algorithms to automatically score essays. I won’t try to dance around the issue; I initially competed because I noticed that some extremely smart people were in it, and I wanted to see how I stacked up. But as time went on, I became more and more invested in the subject, and began to recall my own experiences with higher education and writing.
I was fortunate enough to be able to work with Justin Fister, and we ended up coming in 3rd place out of 156 teams in the competition. Most of the major assessment companies (think Pearson, McGraw-Hill, etc) also participated, but more on this later. In a second competition for short answers, we teamed up with Measurement, Inc. (MI), and came in first place on the leaderboard, although we were ineligible for prizes due to our company affiliation. You can find the excellent papers from the winners, as well as their code, here.
As strange as it sounds, even though I was sitting at my computer, coding for hours on end, participating in those competitions was a lot of fun. I was able to spend every day learning, striving, and implementing (I may have had a less rosy recollection had I not done so well). But the luster quickly faded post-contest. We had made some interesting advances, and now possessed a lot of knowledge, but so what? The knowledge was not being applied to anything, and there is a huge gap between theoretical and real-world results. Justin found a job at MI, and I went to work for edX, a massively open online class (MOOC) provider based in the Boston area, where I started to apply what I learned.
You may have heard of the edX automated essay scoring algorithm, and the backlash such as this and this to it and AES. I created this algorithm, and as much as the criticism can sting or get really strange (the guy who wrote the first backlash article I linked to decided to call it first year graduate student level, which I guess he thinks is an insult), I think that there are valid points on both sides of the issue, and I will try to go through them in my discussion.
What is AES?
To me, AES is the art of giving students automatic, iterative, and correct, scores and feedback on their essays and constructed responses. You may notice that I inserted several concepts that go beyond the narrow scope contained in the words “automated essay scoring”. I will go through each one in order:
- Feedback - in many applications of AES, such as in a “second reader” role on the GMAT(more on what this is later), feedback isn’t as important. But in all cases where a student will be learning based on how their response is scored, feedback is absolutely critical.
- Iterative - One of the main advantages of AES is that students can submit their response as many times as they want, getting very quick feedback and scoring each time.
- Constructed responses - Automated scoring isn’t just about essays. As the second Hewlett Foundation competition showed, computers can grade constructed responses as well.
- Correct - Automated essay scoring is somewhat useful if its scores are only marginally inaccurate, but its utility goes away if it can’t score properly.
Now, maybe you don’t agree with my definition, but at least we have a baseline idea of what it is for when we proceed through this article. If you don’t agree with this, I would love to hear what your definition is, and how you think this definition can be made better.
A brief history of AES
Remarkably, the idea of AES first came about in 1966, and was advanced by Ellis Page. Amazingly, it only took him two years to come up with working software. I can’t even imagine how much ingenuity it must have taken to do what he did with the hardware/software limitations of the time. His software, called Project Essay Grade (PEG), was later purchased by Measurement, Inc., which continues to develop it.
Through the 1990s and 2000s, several other companies, such as Educational Testing Service, Pearson, and CTB/McGraw-Hill, started developing their own tools. Some open tools, such at BETSY, also appeared. ETS in particular has published a lot of interesting papers, which you should check out if you are interested.
One major use case of these tools was as an automated “second reader” for high stakes tests. A human first scored the test, after which a machine scored it. If the two scored differed by a certain amount, then a third human re-scored the paper to resolve the dispute. Another major use case was as an in-classroom learning tool. In fact, these are still the primary use cases for AES.
How does AES work?
Here is a rough diagram of automated essay scoring:
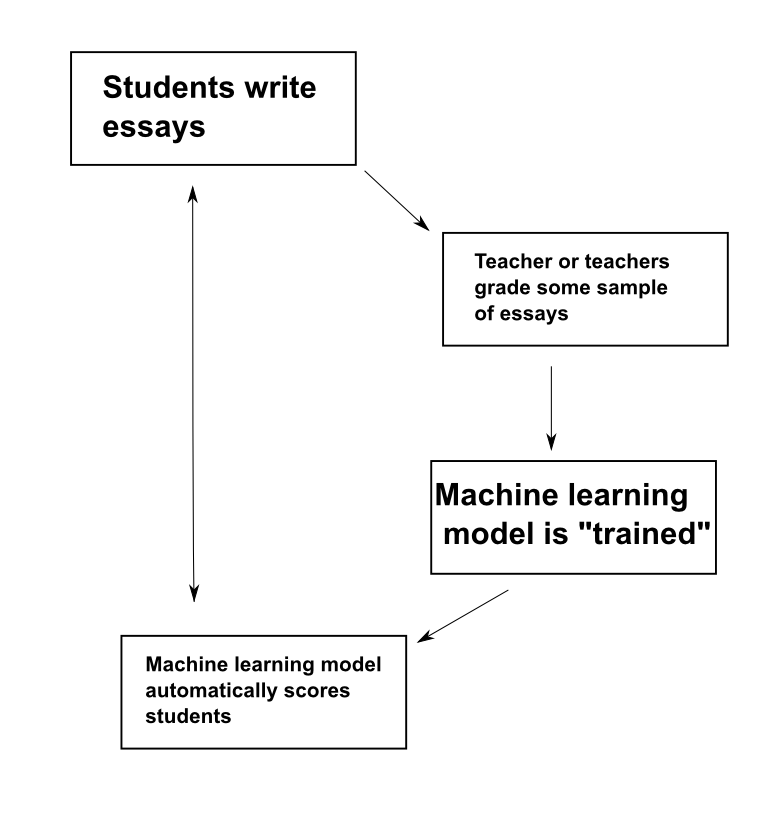 So, students first write some essays. Teachers then grade these essays using whatever criteria they want and a machine learning model is created.
So, students first write some essays. Teachers then grade these essays using whatever criteria they want and a machine learning model is created.
A machine learning model differs from a machine learning algorithm. A machine learning algorithm is a blank slate that can be trained to do a certain task. To make a bit of a stretch analogy, think of it as a computer brain – it is capable of learning something, but it doesn’t know how to do it yet. We then train this algorithm, this computer brain, to score essays. After it has been trained, it gives us a machine learning model, which can be used to score more essays.
In order for a machine learning model to be created, features first need to be extracted from the text, as a computer cannot directly understand English. We need to use the numbers as proxies for meaning.
Features are just numbers that describe certain things. For example, in my current apartment, one feature is that it has 1.5 bathrooms, and another feature is that it has 2 bedrooms. If I was going to build a machine learning model to predict apartment rents, I might pass in these features. I would then map the features to a certain amount of rent. So, for example, if one apartment has 1.5 bathrooms and 2 bedrooms and costs 1,000 dollars a month in rent, whereas another apartment has 1 bathroom and 1 bedroom and costs 500 dollars a month in rent, a machine could learn that a certain number of bedrooms and a certain number of bathrooms equal a certain amount of rent. So, if we ask it to predict the rent for an apartment with 1 bathroom and 2 bedrooms, it might say 900 dollars.
Let’s look at this is the context of essays, using some examples from a presentation I did last month:
Say that I wanted to give a survey today and ask you why do you want to learn about machine learning?
The responses might look like this:
I like solving interesting problems.
What is machine learning?
I'm not sure.
Machine learning predicts everything!
Let’s say that the survey also asks people to rate their interest on a scale of 0 to 2.
We would now have the responses and associated interest scores:
numberresponsescore1I like solving interesting problems.22What is machine learning?03I'm not sure.04Machine learning predicts everythingSo, let’s say that we get a half-filled-out survey that forgot to include the interest score. All we got was the sentence I really like solving problems. Machine learning is very useful. Now, if we look at this in the context of the other responses, we can infer that the interest of the person is likely a 2/2. But how would a computer do the same thing? Through features.
Some of the features we might extract:
- Presence/absence of the phrase
solving problems. (0 if absent, 1 if present) - Number of sentences.
- Presence/absence of
machine learning. - Average word length.
- Presence/absence of
machine.
This is a very simple example, but it gives you a good idea of what features are. Features allow us to represent text, which a machine does not understand, as numbers, which it does understand.
We can then tell a machine learning algorithm, such as a random forest, or a linear regression, that a certain sequence of features means that the teacher gave the student a 2, another sequence of features means that the teacher gave the student a 0, and so on. This trains the algorithm, and gives us a model.
Once the model is created, then it can predict the scores for new essays. We would take a new essay, turn it into a sequence of features, and then ask our model to score it for us.
As you can see, what the model is trying to do is mimic the human scorer. The model is figuring out how an expert human scorer grades an essay, and then trying to apply that same criteria to other essays. So, it isn’t actually a machine judging essays on arbitrary criteria; its a machine trying to figure out the criteria a human uses to score essays, and then apply those criteria to grade other essays.
More on this is beyond the scope here, but I recently did a talk about AES, and also have a tutorial on my blog, both of which I highly encourage you to check out if you are interested.
Applying AES
Now that I have given you the theory, let’s talk about application. Here is a diagram of how we grade essays and constructed responses at edX:
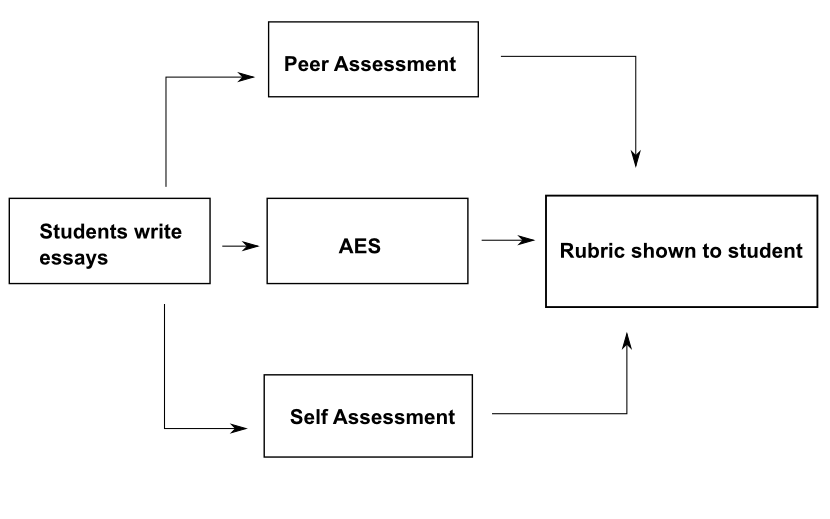 So, when a student answers a question, it goes to any or all of self, peer, and AES to be scored. Written feedback (from peer assessment), and rubric feedback (from all three assessments) are displayed to the student.
So, when a student answers a question, it goes to any or all of self, peer, and AES to be scored. Written feedback (from peer assessment), and rubric feedback (from all three assessments) are displayed to the student.
It is completely up to the instructor how each problem is scored, and how the rubric looks. Here is an example rubric (I’m not good at making rubrics, so it’s not excellent):
Topicality
0 points - Student is off topic
1 point - Student stays on topic
Photosynthesis
0 points - Incorrectly defines photosynthesis
1 points - Partially correct definition
2 points - Fully correct definition
The AES would tell you how you did on each of the rubric dimensions (which are customizable by the instructor).
Here is specifically how the AES works:
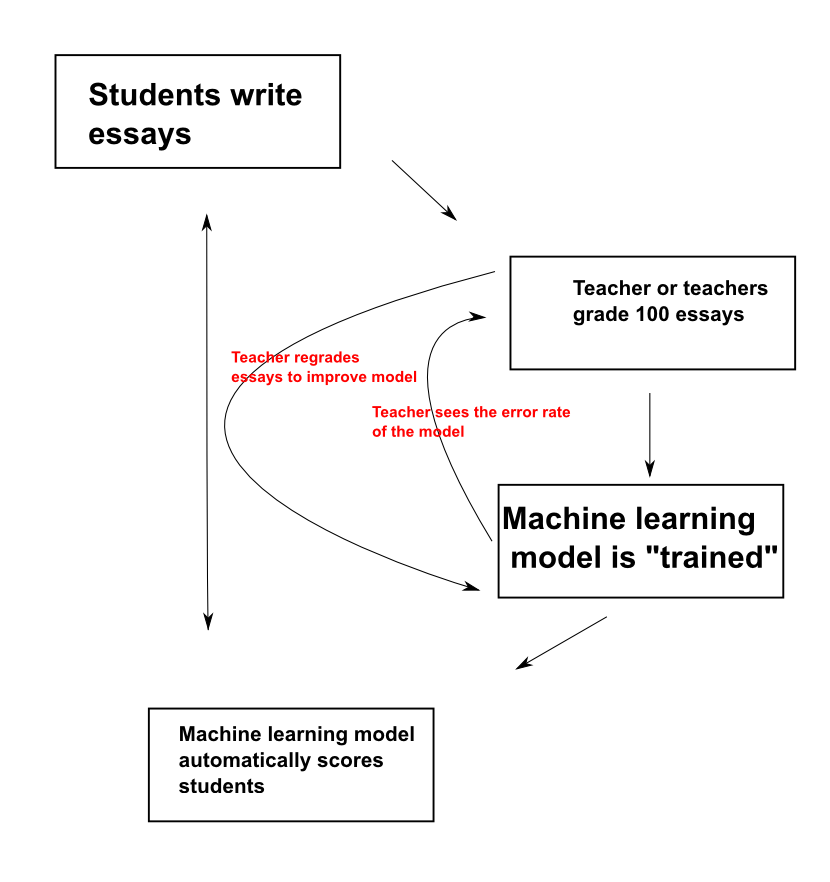 The main difference between this and the generic workflow I showed you before is that edX allows teachers to regrade essays that AES has scored poorly. When a machine learning model scores an essay, it doesn’t just give you a score; it also gives you a confidence value from 0% - 100% associated with that score. A low confidence indicates that the machine learning model does not know how to score a given essay well. We show student papers that AES has already graded to the teacher, in order of lowest confidence to highest. When a teacher re-scores a paper, it gives the student the correct score, and makes the machine learning model better (it won’t make the same mistake twice). This is called active learning.
The main difference between this and the generic workflow I showed you before is that edX allows teachers to regrade essays that AES has scored poorly. When a machine learning model scores an essay, it doesn’t just give you a score; it also gives you a confidence value from 0% - 100% associated with that score. A low confidence indicates that the machine learning model does not know how to score a given essay well. We show student papers that AES has already graded to the teacher, in order of lowest confidence to highest. When a teacher re-scores a paper, it gives the student the correct score, and makes the machine learning model better (it won’t make the same mistake twice). This is called active learning.
The AES will give the student feedback on how many points they scored for each category of the rubric. I show you this example less to discuss the strengths and weaknesses of the edX system (it has both), but more to lead into a discussion of how, when, and why AES should be deployed.
Lessons of application
I personally have learned a lot of lessons in both developing and applying AES algorithms. Below are some, in no particular order. I talk about the edX system a lot, because I have a lot of recent experience with it.
Don’t forget the goal
The goal here isn’t to impress people with fancy technology or tell teachers how they should teach. The goal is to maximize student learning and limited teacher resources (time) in a way that is flexible, and under the control of the subject expert (teacher).
Scale
In a MOOC setting, AES makes sense. It is hard/impossible for a teacher to score thousands of students each week, and writing is a critical component of many courses. But scale can also play a big part in the classroom. Can a teacher grade 10 drafts per student per week? Maybe it makes sense to allow students to score their “intermediate revisions” with AES, improve their writing, and give their key drafts and finished products to a teacher for more detailed feedback.
AES is (mostly) best used in combination with other ideas/technologies/concepts
In the same vein as the point above, AES is useful in some domains, and can given students accurate scores and rubric feedback. However, AES cannot give detailed feedback like an instructor or peer can. You should evaluate your options and see how you can best use AES. Maybe it works for certain questions. Maybe you can grade tests with AES. Maybe it is good for grading first drafts. Maybe you should combine it with small group discussions or peer scoring. If the tools are built properly, it will be possible to evaluate all these options, and figure out which one, if any, has the most value for students.
Put the power in the hands of teachers
AES is useless when the power is in the hands of researchers and programmers (although it does make us feel important). The real people who need to shape and implement these technologies are teachers and students, and they need the power to define how the AES looks and works. Maybe a teacher doesn’t need to define what features the AES uses, but being able to turn off the AES for certain students might be useful.
Give people the information that they need
AES is a semi-shadow world to a lot of people, and that may be partially by design. The less we tell people about how things are done, the more valuable and important we become. I am always leery of researchers who take the “non-cooperative expert” stance. All of the software I developed/helped develop at edX is open source, and I have been open sourcing all of my recent personal work. But just open source is not enough. We need to discuss what the code is doing, build up documentation around it, and most critically, allow people to contribute to it, to make it truly useful. The Hewlett Foundation, and particularly Vic Vuchic, have done some great work here, and I hope it is continued.
Have the algorithm tell people how it is working
Algorithms can estimate their own error rates (how many papers they grade correctly vs incorrectly). At edX, these error rates are displayed to teachers, so that teachers can make the machine learning models better if they want to. Giving teachers and students as much information as possible within an AES system is key. If we don’t know how something is working, how can we tell if it is doing what we want?
It’s not all about the algorithm
Most of the time I spent creating the edX open response assessment tool was spent on things that don’t have to do with the algorithm. Algorithms are fun and exciting, but learning tools are only useful if they help students, well, learn. The most important thing in this is usability. Can a student quickly digest and use their feedback? Can a teacher quickly create a new problem and deliver it to students? It is actually pretty easy to implement an algorithm. It is hard to put the things in place around it to allow students to succeed. I would even venture to say that once you get a certain level of accuracy in your algorithm, improving usability should become the primary goal.
Make everything usable
Is the product designed for teachers or for “expert” researchers? Does a user have to manually read a ton of essays into a command line or GUI program (think Microsoft office)? How do students get papers into the system? At edX, everything is a web-based tool, and students can write papers and receive feedback entirely through a web interface. Teachers can create problems that use AES in a few clicks, and can grade student papers through a web interface. This isn’t the end all be all of ways to approach this, but more user friendly is better.
Grading isn’t all about essays
Can we grade uploaded videos? How about pictures or songs? This can be done with peer and teacher grading, but AES needs to be extended to work with alternative media as technology advances.
Keep coming up with new ideas
I alluded earlier to several large assessment companies participating in the Kaggle essay scoring competition. In fact, these companies were the American Institutes for Research, Carnegie Mellon University (Lightside), CTB/McGraw-Hill, Educational Testing Service (ETS), MetaMetrics, Measurement, Inc., Pearson, Pacific Metrics, and Vantage Learning. The Carnegie Mellon (CMU) tool is and was open source, but crucially, it does not appear to be open information or open contribution (edit: Elijah Mayfield points out in the comments that the Carnegie Mellon tool is on bitbucket, and is open contribution). The vendors and the teams didn’t compete on exactly the same leaderboard, and you can read more about the results here, but the algorithms of the vendors and the competition participants were evaluated on the same data sets (edit: Shayne Miel, referenced below, has told me that the vendors were evaluated on a slightly different data set. However, there were advantages on both sides, as vendors got to talk to the Hewlett Foundation about the data several times).
Competitors and vendors were ranked by quadratic weighted kappa (QWK), which measures how closely the predicted scores from the models matched up with human scores (higher kappas are better). We can summarize the performance with this excellent charts from Christopher Hefele:
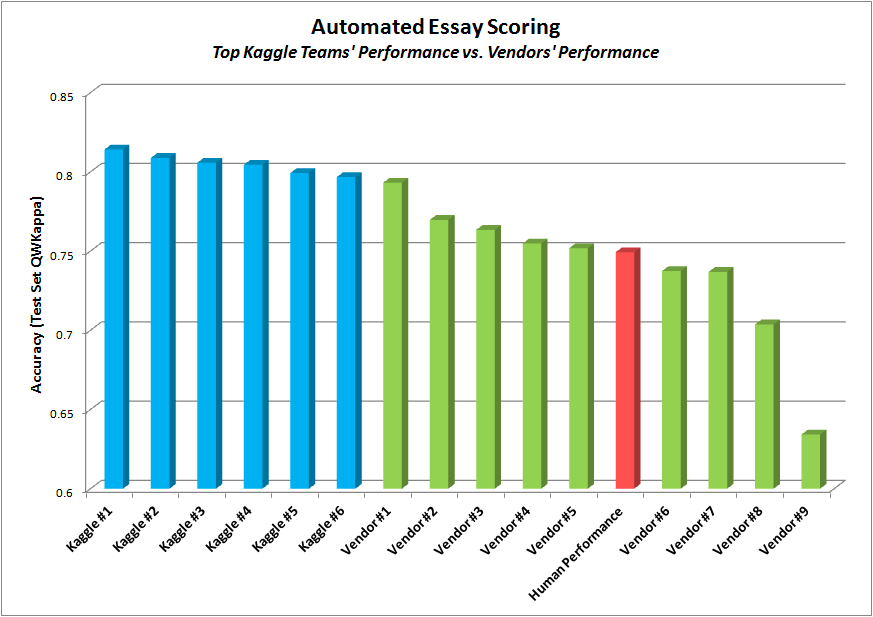 We can see that the top six competition participants did better in terms of accuracy than all of the vendors. I have discussed before what I think of accuracy as the sole metric for AES success, so take this with a bit of salt. The main reason I show this is to illustrate that open competition, with a fair target, can lead to very unexpected results and breakthroughs.
We can see that the top six competition participants did better in terms of accuracy than all of the vendors. I have discussed before what I think of accuracy as the sole metric for AES success, so take this with a bit of salt. The main reason I show this is to illustrate that open competition, with a fair target, can lead to very unexpected results and breakthroughs.
Even the open source solution from CMU that was included in the competition scored a QWK of .7538, good for only 19th place on the final leaderboard, which indicates that it is less about open source than about open information, access, and competition (observant readers may notice that the guy who made the CMU tool is the same guy who called my code “first year graduate student level” and disparaged the edX tool. I note this only to acknowledge potential bias – I do not think I am biased in thinking that open information is key, but I may be wrong, and let me know if you think I am).
I think that the best results come about when fresh ideas can be combined with existing knowledge and expertise. There are some extremely bright people in the AES industry that I have been fortunate enough to meet and/or work with, such as Chris Brew, Shayne Miel, David Vaughn, and many more. When Justin and I teamed up with Shayne and David, we ended up doing very well in the second Hewlett Foundation competition.
This second chart, also from Christopher, is also interesting:
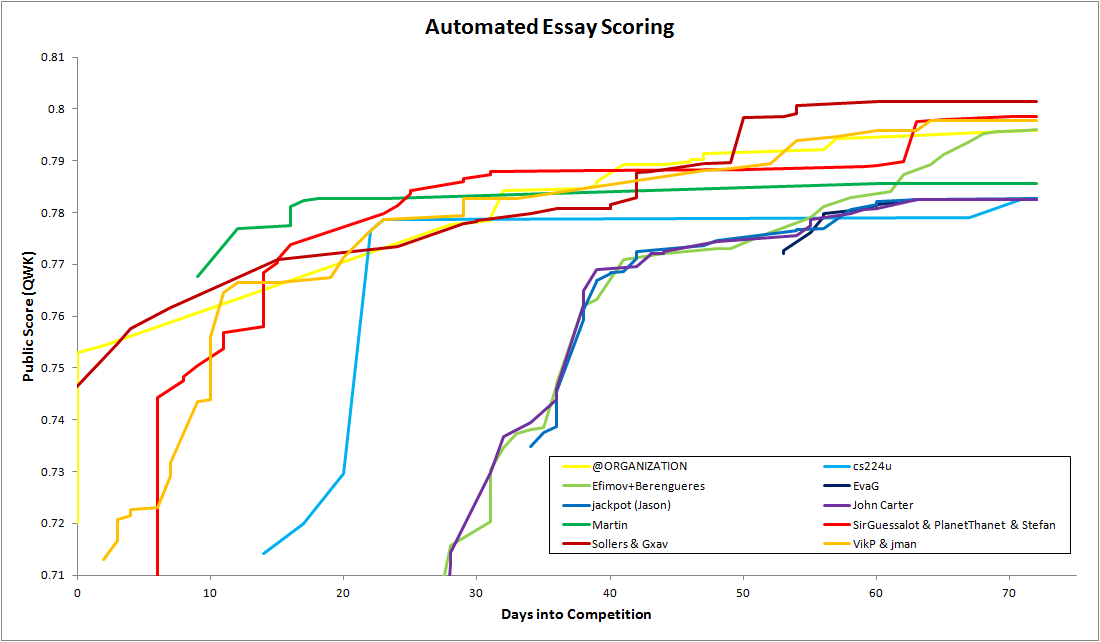 Each line is how one of the top competitors performed on the public leaderboard (essentially us testing our algorithms before the final evaluation). Looking at the “VikP & jman” line, which is the line for my team, brings back some memories of frantic coding and thinking up crazy solutions to increase accuracy.
Each line is how one of the top competitors performed on the public leaderboard (essentially us testing our algorithms before the final evaluation). Looking at the “VikP & jman” line, which is the line for my team, brings back some memories of frantic coding and thinking up crazy solutions to increase accuracy.
We can see how performance changes over time, as algorithms got more and more accurate. But only up to a certain point. The data that we worked with in the competition to train our algorithms was limited – we could not create more. What you are seeing is everyone converging on a maximum theoretical accuracy. After this point, there is not much more that can be achieved (which is another reason why I think things other than accuracy should be more emphasized).
I went through all of this to get to a relatively straightforward point – we need to make tools that are open and usable, and we need to make information readily available. I have a strong feeling that doing this will lead to breakthroughs and new directions that nobody has thought of yet.
Everything else I didn’t think of
There are many more lessons to be learned. Let me know if you think of any.
The bright future
The Hewlett Foundation has been doing some excellent work in the AES space, and I know that they are planning in-classroom trials of various AES products. Unfortunately, I believe that the group of products has already been picked, and is mostly commercial products or “established” products.
Some scenarios that I hope emerge out of this trial and others are below. Some of these are already being done to varying degrees:
- AES is used as a way to give students iterative feedback before submitting a final draft to a teacher for a full evaluation. Does this help learning?
- AES systems experiment with giving teachers information, and allowing them to regrade and customize grading.
- Automated systems pre-score essays, and automatically identify students who might need teacher intervention.
- A teacher scores an essay, then is given the score the same essay received via AES, and can update their score if they believe that the AES brings up useful points.
- Small group discussions and peer grading are tried in combination with AES.
- Automated scoring of alternative types of media, like videos, begins to emerge.
Hopefully I have given you a good idea of what AES is, and what it can do, and how it might look in the future. Please let me know if you have any questions or want to share something. You can find me in a ridiculous amount of places: the comments section here, twitter (@VikParuchuri), linkedin, and email (vik dot paruchuri at gmail). Pick one.
