Predicting NBA Playoff Games - Results and Update 1
Game Results
I recently made a post about [developing an algorithm](http://viksalgorithms.blogspot.com/2012/05/predicting-nba-finals- with-r.html) to predict the NBA playoffs, and I concluded with 2 predictions. Although Miami beat the Celtics to make my algorithm 1-0 in terms of predictions, it fell to 1-1 when the Thunder beat the Spurs. So, we are now at .500 . Considering that the algorithm was about 61.5% accurate over the whole season, this is to be expected.
I made some improvements to the algorithm which improved accuracy, and then used this to make new predictions for the next game in each of the current series (Spurs vs. Thunder and Celtics vs. Heat). You can scroll down all the way to see the predictions, or read through to see what I did.
Improvements in Variables
I created rough code initially, and I didn’t fully utilize all of the information that I had. The first step in making improvements was to add some variables relating to different player positions and bench vs. starter performance.
For example, this plot shows that the average number of seconds bench players played over the last 10 games has a decent correlation with winning percentage:
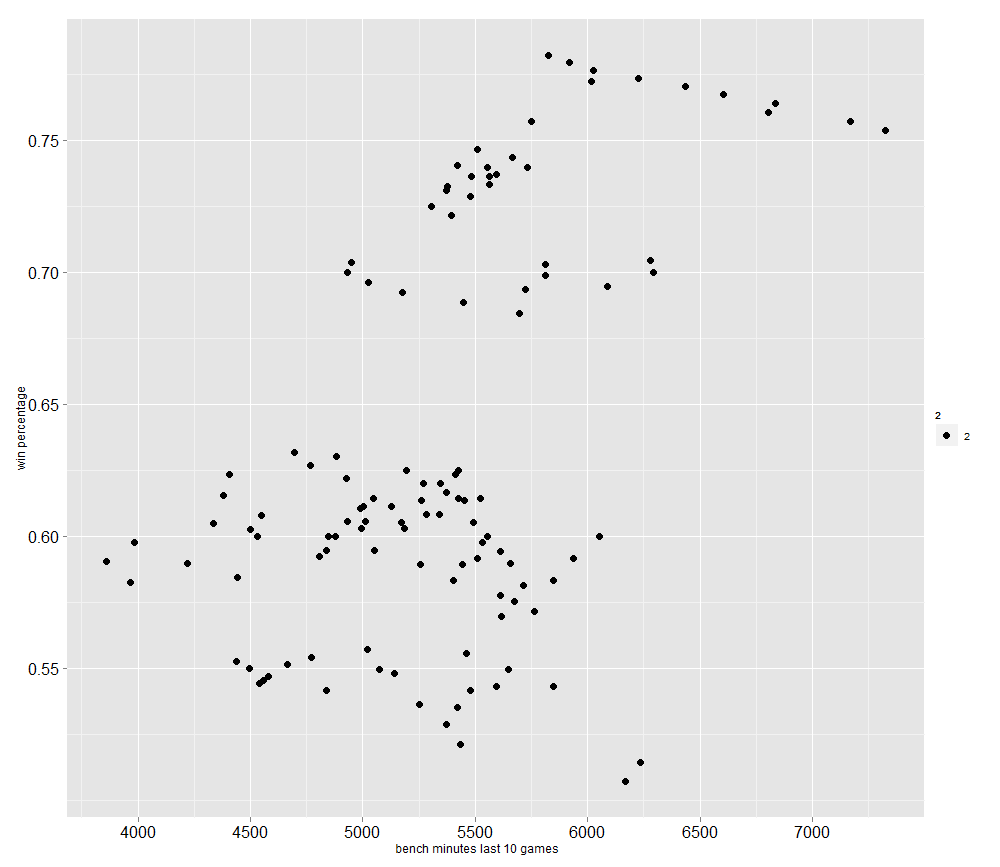 A reasonable conclusion to this is that winning teams generally have a stronger bench that they can rely on more.
A reasonable conclusion to this is that winning teams generally have a stronger bench that they can rely on more.
Improvements in Machine Learning
After adding some variables, I moved on to adjusting the models that I used. I had initially spent very little time on the machine learning framework, and most of the time on the data, and that did not change here, but I was able to tweak what I was predicting. Initially, I was predicting a binary value- whether a team won or not. I adjusted this to predict the ratio between a team’s score and another team’s score. This gave the machine learning algorithms a lot more information than a 1/0 target, and also had the benefit of being a normal distribution, as this quantile-quantile plot shows:
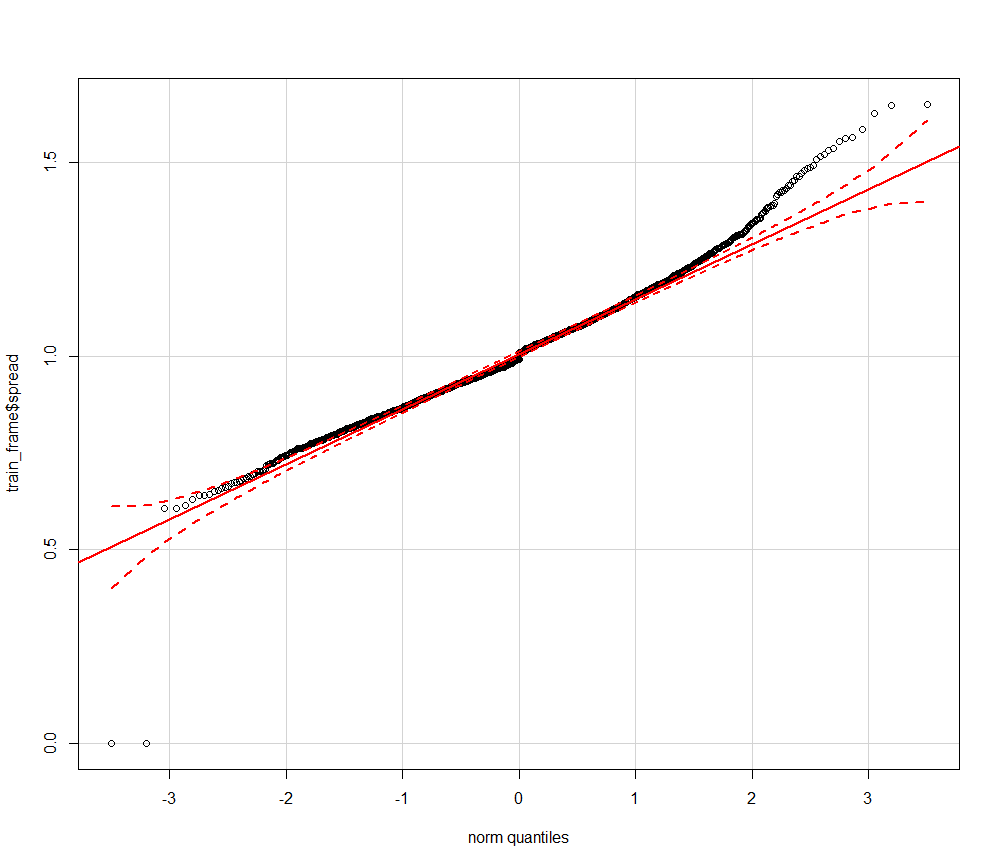 The straight red line is a normal distribution, and this is very close, which makes it an ideal target variable. After the machine learning algorithms predicted this, I was able to combine the results via a simple mean method and convert them to binary win/loss values. This made the algorithm much more accurate than before.
The straight red line is a normal distribution, and this is very close, which makes it an ideal target variable. After the machine learning algorithms predicted this, I was able to combine the results via a simple mean method and convert them to binary win/loss values. This made the algorithm much more accurate than before.
Updated Season Accuracy Results
With the improvements, the accuracy now comes to 63.6% for the season, which is a reasonable improvement over the previous results. This results in this confusion matrix:
 The main hindrance to accuracy is only being able to get team names and home/away information for future games. If it was possible to get more information, such as officials, lineups, etc, it would be possible to make a much more accurate model. Having more data from past seasons would also help a lot, and I might look into getting that.
The main hindrance to accuracy is only being able to get team names and home/away information for future games. If it was possible to get more information, such as officials, lineups, etc, it would be possible to make a much more accurate model. Having more data from past seasons would also help a lot, and I might look into getting that.
Predictions for Upcoming Games
As before, I will leave you with predictions for the two upcoming games.
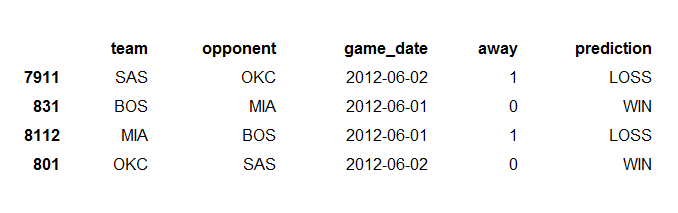 Here, the algorithm is predicting a Boston win/Miami loss, and an Oklahoma City win/San Antonio loss. Let’s see how it plays out!
Here, the algorithm is predicting a Boston win/Miami loss, and an Oklahoma City win/San Antonio loss. Let’s see how it plays out!
I can do a decent amount of analysis on the data, so please let me know if you want to see something specific next time. I’m going to make posts predicting all of the games in the series and the finals.
