Do the Simpsons characters like each other?
One day, while I was walking around Cambridge, I had a random thought – how do the characters on the Simpsons feel about each other? It doesn’t take long to figure out how Homer feels about Flanders (hint: he doesn’t always like him), or how Burns feels about everyone, but how does Marge feel about Bart? How does Flanders feel about Homer? I then realized that I work with algorithms – maybe I would be able to devise one to answer this question. After all, I did something similar with the Wikileaks cables.
This idle thought led me down a very deep rabbit hole. The most glaring problem was that no full scripts of the Simpsons exist. There are full transcripts of each episode, with no information on who is speaking each line.
I first tried using natural language processing techniques to determine who was speaking each line. This worked reasonably well, but I felt that it was still missing something. I then directly analyzed the audio from the episodes to figure out the “voice fingerprints” for each character, which I used to label the lines. This was better than just looking at the text of the lines. I wanted to combine these techniques, but ran out of time. It can be fairly easily done at some later date to increase accuracy.
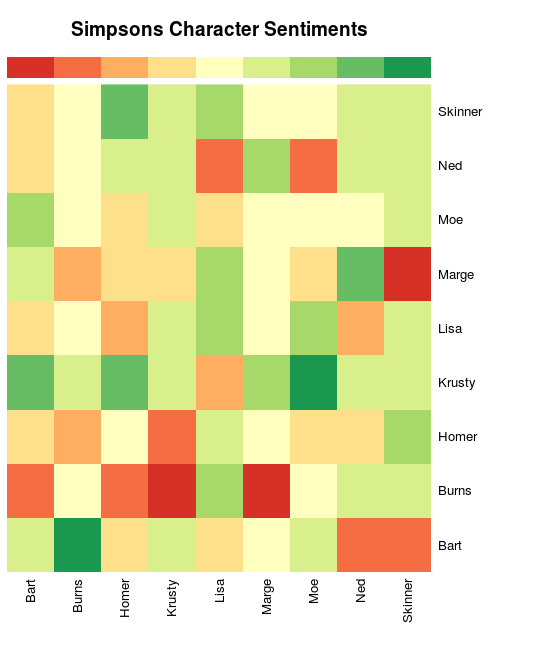
From the labelled lines, we can determine how much each of the characters likes the rest. If you want to skip ahead, the heatmap of how much the characters like each other is below. It shows how much each character in the row likes each character in the column. Some characters may feel differently about each other (for example, check out Krusty and Lisa). Red indicates dislike, and green indicates like.
Methodology
To get sentiment from the scripts, we first get the AFINN-111 word list. This word list associates specific words with sentiment scores. Here is an excerpt:
1479 luck 3
1480 luckily 3
1481 lucky 3
1482 lugubrious -2
1483 lunatic -3
1484 lunatics -3
1485 lurk -1
A negative sentiment score means that a word is associated with bad feelings, and vice versa.
We can then use a principle called random indexing to build up vectors for positive and negative sentiment. Random indexing assigns a unique vector to each word. The vector is called the random index. We can then add all of the random indices where the sentiment score is under a certain amount up to get the “negative sentiment vector.”
So, let’s say that the first vector is the random index that we assign to “lunatic”, and the second is the random index we assign to “lurk.” We can add these up to get a negative sentiment vector that contains information about both words. This will serve as our “dictionary.” If we compare another vector to this and their similarity is high, then the other vector likely has negative sentiment.
If we have a sentence The lunatic is here, we can tokenize it (break it up into words). We then are left with ['The', 'lunatic', 'is', 'here']. We throw away the tokens that aren’t in our AFINN word list, leaving us with ['lunatic']. We then build up a sentence vector for this specific sentence, in this case [0,1,1,0].
We can then compare our sentence vector to the negative sentiment vector using any distance metric to find out how similar they are. Using cosine similarity, we discover that these score a .866 out of 1, indicating that they are very similar. We can do the same on the positive side to figure out positive sentiment.
Application
We will apply a slight variation of this to our problem. After labelling the scripts, I was left with this:
start end season episode line result_label
599 393.76 396.04 5 8 All I've gotta do is take this uniform back after school. Bart
600 396.16 399.92 5 8 You're lucky. You only joined theJunior Campers. Milhouse
601 400.04 403.60 5 8 I got a dirty word shaved into the back of my head. Bart
602 403.72 406.52 5 8 [ Gasps ] What is it with you kids and that word? Skinner
603 406.64 408.84 5 8 I'm going to shave you bald, young man... Skinner
604 408.96 412.76 5 8 until you learn that hair is not a right-- it's a privilege. Skinner
Start is how many seconds into the episode the line started, end is when it ended, and result_label is who the algorithm determined spoke a given line. As you can see, the algorithm is not 100% perfect, primarily due to the difficulty of syncing the subtitles up with the audio, and the fact that multiple people can be speaking during a single subtitle line.
We will find the “neighboring characters” for each line that our characters speak to be the character that spoke immediately before and the character that speaks immediately after. So, in our example above, in the first line Bart has, his neighoring character is Milhouse. In his second line, his neighboring characters are Milhouse and Skinner. We can reasonably expect that what a character says indicates their opinion of the neighboring characters – those characters that are in the same scene as them.
For each character, we will then build up a “neighboring character” matrix using our lines.
[,1] [,2] [,3] [,4] [,5]
Bart 1 0 0 0 0
Burns 0 5 3 0 1
Homer 0 0 0 1 0
Krusty 0 0 0 0 0
Lisa 0 4 0 0 0
Marge 1 0 2 0 1
This is the neighboring character matrix for Skinner. Each row is a character whose lines border Skinners. Whenever this happens, we take the words in Skinner’s line that are in the AFINN word list, find their random indices, and add them to the row vectors for the neighboring characters.
601 400.04 403.60 5 8 I got a dirty word shaved into the back of my head. Bart
602 403.72 406.52 5 8 [ Gasps ] What is it with you kids and that word? Skinner
So, in the above excerpt, we would add the random indices from Skinner’s line to Bart’s vector in the neighboring character matrix.
When we finish looping through all of the dialogue lines we can compare each row in the “neighboring character” matrix to the positive and negative vectors to determine how our character felt about each of their neighboring characters.
character pos_scores neg_scores score
1 Bart 0.1921688 0.2053323 -0.0131635369
6 Marge 0.2108304 0.2101996 0.0006308272
3 Homer 0.2852096 0.2524450 0.0327646067
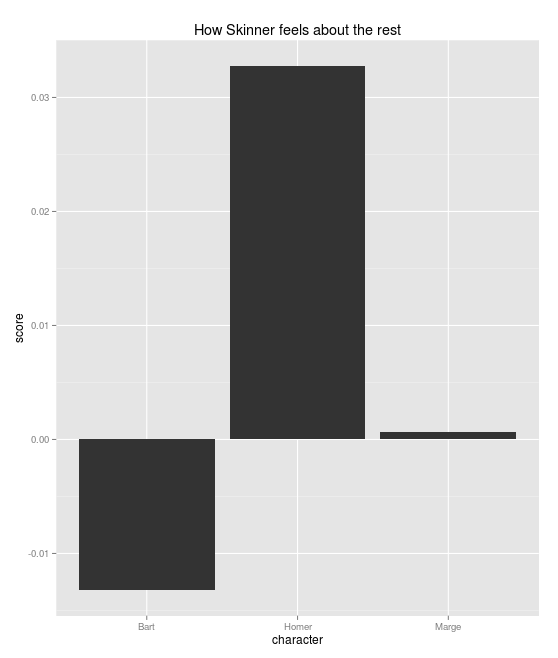
The character is the character from the neighboring character matrix, the pos_score is the similarity between their matrix row and the positive sentiment vector, the neg_score is the similarity between their row and the negative sentiment vector, and score is pos_score - neg_score. So, Skinner appears to dislike Bart, to like Homer, and to be neutral to Marge.
Charts
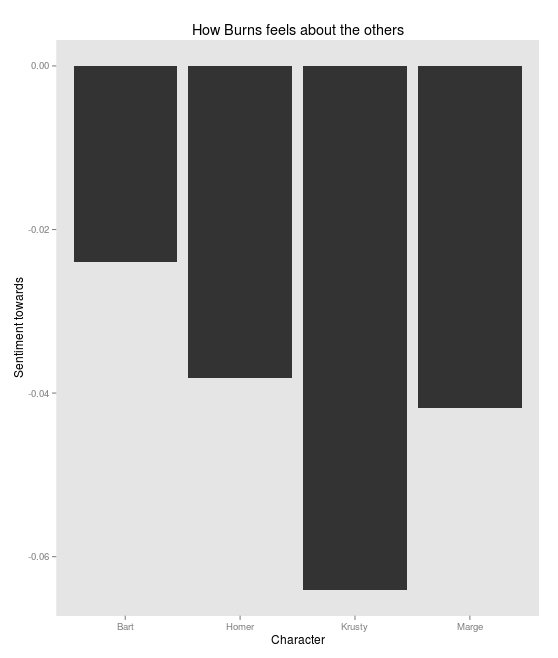
Unsurprisingly, Mr. Burns hates everyone:
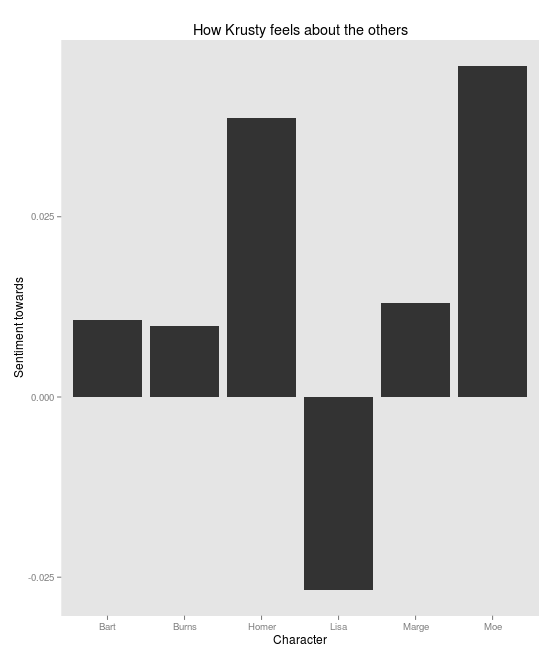
 Krusty is a happy guy, but seems to have a strange vendetta against Lisa:
Krusty is a happy guy, but seems to have a strange vendetta against Lisa:
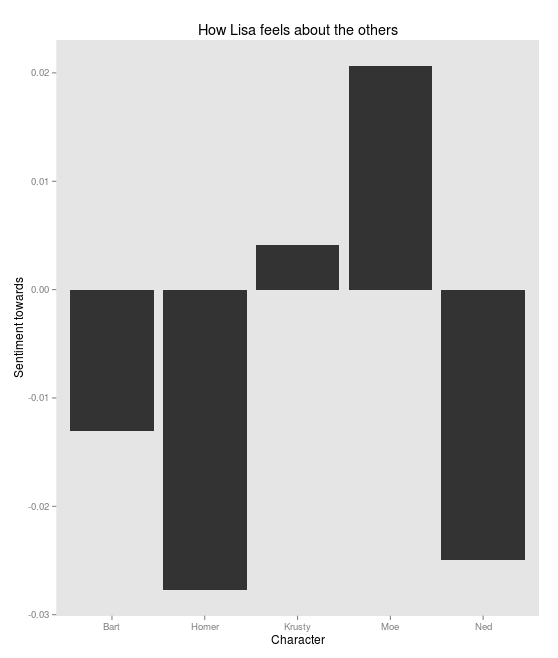
 Oddly, Lisa seems oblivious to this, and still likes Krusty. Although Homer and Bart aren’t her favorites:
Oddly, Lisa seems oblivious to this, and still likes Krusty. Although Homer and Bart aren’t her favorites:
 And Bart really doesn’t like Skinner:
And Bart really doesn’t like Skinner:

Conclusion
This was a fun project to work on. The analysis is definitely noisy and imperfect, but it is still interesting. I would love to hear feedback or suggestions if anyone has them. You can find the code for this here.
